
As organizations handle increasing data, two architectures dominate the conversation. For understanding the data lake vs. data warehouse, debate is not just a technical exercise. It is a strategic business that shapes how you access, store, and monetize the information.
What Is a Data Lake?
So, what is a data lake? For a simple explanation, a data lake is a centralized repository that stores raw data in its native format, like structured, semi-structured, and unstructured, until it’s needed. Think of it like a massive storage pool where you dump everything first and figure out how to use it later.
Unlike a traditional storage system, it does not require a predefined schema. Data is stored in a raw form, like log files, images, JSON, CSV, and social media streams, all in one place. The structure is applied only when the data is accessed, known as schema on read.
What Is a Data Warehouse?
A data warehouse is like a well-organized storage system where data is carefully cleaned, structured, and arranged before being stored, for making sure a high accuracy and fast access with a predefined schema, making it ideal for reporting, business intelligence, and smart decision-making.
Data Lake vs. Data Warehouse: The Difference.
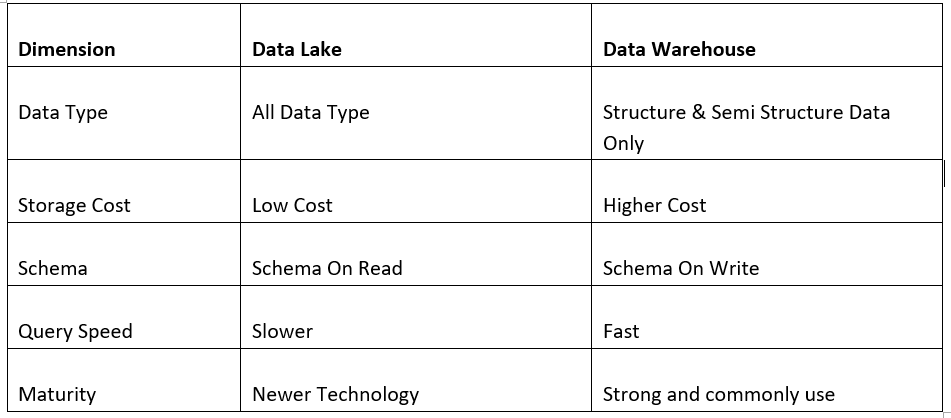
The data lake vs. the data warehouse comparison.
Explaining About the Data Lake Architecture.
Data lake architecture is used quickly to design what is known as “medallion architecture,” where the data flow smoothly through raw, good, and final output. Make the raw data easy to understand and ready for decision-making.
From the data-collecting layer, it is stored in scalable object storage and refined in the processing layer it is organized through delivery to the consumption layer, where it is the power dashboard, report, and machine learning model, turning raw data into real business value.
S3 Data Lake: A Common Foundation for Data Usage.
An S3 data lake is one of the most commonly used foundations for new data architecture; it is offering scalable, secure, and cost-effective storage for massive volumes of data. It is built on Amazon S3 object storage. An S3 allows organizations to store all types of data: structured, semi-structured, and unstructured. In one centralized location, make it easy to manage and access.
With flexibility and low cost, businesses can store raw data without worrying about the storage limit while integrating tools like AWS Glue, Athena, and EMR to organize, analyze, and process data efficiently, forming a powerful data lake and data warehouse. This makes it an ideal choice for analysis, machine learning, and long-term data retention for helping an organization turn raw data into valuable insight.
Data Lake for Enterprise: Practical Use Case.
Data lakes for enterprises provide greater flexibility and power than traditional warehouses alone.
Here’s the common business situation:
- Machine Learning: Teams need access to a big volume to build accurate and intelligent models. A data lake makes such access possible by storing a year of unprocessed data, such as transaction logs and sensor data, in one central place.
- Unified Customer 360: A big organization collects data from different sources like CRM, support tickets, and social media. Bring everything together into a center. This creates a single view of each customer instead of spreading out the information across different systems.
- Regulatory Compliance: Organizations are needed to keep accurate and original data records to meet strict regulatory and audit requirements, and a data lake for enterprise makes this possible by storing raw, unmodified data in its original form and making sure nothing is lost or changed over time.
Practical Example of Data Lake Usage.
For better understanding a new data architecture, look at a real-world example of data lake usage. Make the structure clear and practical. From an e-commerce platform that can track customer behavior to a financial institution that detects cheating in real time.
It helps organizations to store a large amount of raw data and turn it into useful insight.
Powerful Data Lake solutions and Tools.
The world of data lake solutions has evolved rapidly, offering a large organization a platform to store, handle, and analyze a massive volume of data with ease. Today its lead solutions option combines scalability, security, and flexibility. Making them essential for new data guides the organization.
- Secure Cloud Storage: Secure cloud storage is storing your data in a cloud environment where it is protected, encrypted, and safely managed. It makes sure that all your important data, whether structured or unstructured, can be stored safely while still being easily accessible when needed.
- Advanced security: Advanced security in a data lake makes sure that all stored data are protected through encryption, access control, and threat detection, and it also prevents unauthorized access and keeps the important information safe.
Among the most popular data-lacking tools, Netforchoice delivers a powerful and unified analytic environment that bridges the gap between data-lacking flexibility and data warehouse performance. By combining scalable infrastructure and enterprise-grade security. Netforchoice enables organizations to build a modern lake house architecture and transform raw data into fast, reliable, and useful insight.
Data Lake Vs. Data Warehouse: Which One is Right for Your Business?
Choosing between a data lake and a data warehouse depends on your business needs. If your team works with clean, structured data for reporting and dashboards, a data warehouse is the right choice. But if you are focusing on exploring raw data, building machine learning models, and discovering the patterns. It offers the flexibility you need.
In most modern enterprises, both are working together. It stores a large volume of raw data, while a data warehouse delivers fast and structured insight.
Conclusion.
Both the data lake and the data warehouse play a virtual role in new data strategy; one offers flexibility for raw data, while the other delivers speed and structure for insight. The real advantage does not come from choosing one but from combining both effectively.
As the rise of low-house architecture brings this system together, the focus should be on building a strong foundation with clear goals, proper governance, and the ability to turn data into the best decision.




